Aula 4
- Hexadecimal
- Ponteiros
- String
- Comparar e copiar
- valgrind
- Troca
- Layout da memória
- get_int
- Arquivos
- JPEG
Hexadecimal
- Na semana 0, aprendemos sobre binário, um sistema de contagem com 0s e 1s.
- Na semana 2, falamos sobre a memória e como cada byte tem um endereço ou identificador, então podemos nos referir a onde nossas variáveis são armazenadas.
- Acontece que, por convenção, os endereços da memória usam o sistema de contagem hexadecimal, onde existem 16 dígitos, de 0 a 9 e de A a F.
-
Lembre-se que, em binário, cada dígito representava uma potência de 2:
128 64 32 16 8 4 2 1 1 1 1 1 1 1 1 1- Com 8 bits, podemos contar até 255.
-
Acontece que, em hexadecimal, podemos contar perfeitamente até 8 bits binários com apenas 2 dígitos:
16^1 16^0 F F- Aqui,
Fé um valor de 15 em decimal, e cada lugar é uma potência de 16, então o primeiroFé 16^1 * 15 = 240, mais o segundoFcom o valor de 16^0 * 15 = 15, para um total de 255.
- Aqui,
-
E
0Aé o mesmo que 10 em decimal, e0Fo mesmo que 15. Em hexadecimal,10seria 16, e nós diríamos "um zero em hexadecimal" ao invés de "dez", se quiséssemos evitar confusão. - O sistema de cores RGB também usa hexadecimal por convenção para descrever a quantidade de cada cor. Por exemplo,
000000em hexadecimal significa 0 de cada vermelho, verde e azul, para uma cor preta. EFF0000seria 255, ou a quantidade máxima possível de vermelho. Com diferentes valores para cada cor, podemos representar milhões de cores diferentes. - Na escrita, podemos também indicar que um valor está em hexadecimal ao prefixar com
0x, como em0x10, onde o valor é igual a 16 em decimal, diferentemente de 10.
Ponteiros
- Podemos criar um valor
ne imprimi-lo:
```
include
int main(void) { int n = 50; printf("%i\n", n); } ```
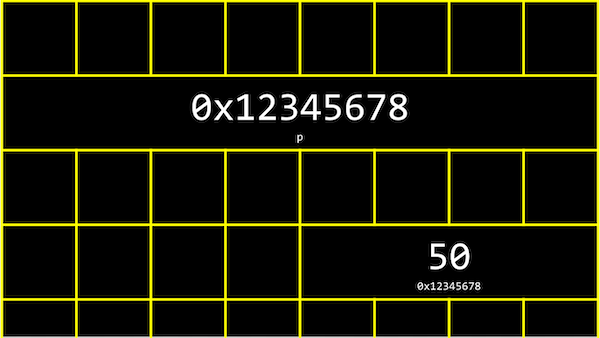
- Na memória do nosso computador, existem agora 4 bytes em algum lugar que têm o valor binário de 50, etiquetados
n: grade representando bytes, com quatro caixas juntas contendo 50 com um pequeno n embaixo - Acontece que, com bilhões de bytes na memória, esses bytes para a variável
ncomeçam em algum endereço exclusivo que pode parecer como0x12345678. - Em C, podemos realmente ver o endereço com o operador
&, que significa "obter o endereço desta variável":
{kind=link}
```
include
int main(void) { int n = 50; printf("%p\n", &n); } ```
-
E no CS50 IDE, podemos ver um endereço como
0x7ffe00b3adbc, onde este é um local específico na memória do servidor. -
O endereço de uma variável é chamado de ponteiro, que podemos considerar como um valor que "aponta" para um local na memória. O operador
*nos permite "ir para" o local para o qual um ponteiro está apontando. - Por exemplo, podemos imprimir
*&n, onde "vamos" para o endereço den, e isso imprimirá o valor den,50, já que esse é o valor no endereço den:
```
include
int main(void) { int n = 50; printf("%i\n", *&n); } ```
- Também temos que usar o operador
*(de uma forma infelizmente confusa) para declarar uma variável que queremos que seja um ponteiro:
```
include
int main(void) { int n = 50; int *p = &n; printf("%p\n", p); } ```
-
Aqui, usamos
int *ppara declarar uma variável,p, que tem o tipo*, um ponteiro, para um valor do tipoint, um inteiro. Então, podemos imprimir seu valor (algo como0x12345678), ou imprimir o valor em seu local comprintf("%n\n", *p);. -
Na memória do nosso computador, as variáveis podem ser semelhantes a isto: grade representando bytes, com quatro caixas juntas contendo 50 com um pequeno 0x12345678 embaixo, e oito caixas juntas contendo 0x12345678 com um pequeno p embaixo
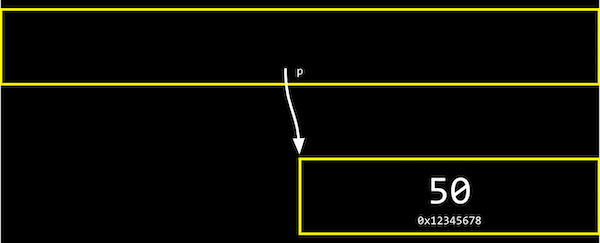
- Temos um ponteiro,
p, com o endereço de alguma variável. - Podemos abstrair o valor real dos endereços agora, já que eles serão diferentes conforme declaramos variáveis em nossos programas, e simplesmente pensar em
pcomo "apontando" para algum valor: uma caixa contendo p apontando para uma caixa menor contendo 50 - Digamos que temos uma caixa de correio rotulada "123", com o número "50" dentro dela. A caixa de correio seria
int n, pois armazena um inteiro. Podemos ter outra caixa de correio com o endereço "456", dentro da qual está o valor "123", que é o endereço da nossa outra caixa de correio. Isso seriaint *p, já que é um ponteiro para um inteiro. - Com a capacidade de usar ponteiros, podemos criar diferentes estruturas de dados, ou diferentes maneiras de organizar dados na memória que veremos na próxima semana.
- Muitos sistemas de computador modernos são "64 bits", o que significa que usam 64 bits para endereçar a memória, portanto um ponteiro terá 8 bytes, o dobro do tamanho de um inteiro de 4 bytes.
{kind=link}
{kind=link}
string
- Poderíamos ter uma variável
string spara um nome como "EMMA" e poder acessar cada caractere coms[0]e assim por diante:![Caixas lado a lado, contendo: E rotulado s[0], M rotulado s[1], M rotulado s[2], A rotulado s[3], \0 rotulado s[4]](https://cs50.harvard.edu/x/2020/notes/4/s_array.png)
- Mas acontece que cada caractere é armazenado na memória em um byte com algum endereço, e
sé na verdade apenas um ponteiro com o endereço do primeiro caractere: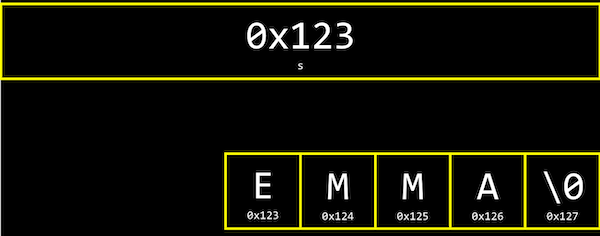
- E como
sé apenas um ponteiro para o começo, somente o\0indica o fim da string. - De fato, a biblioteca CS50 define uma
stringcomtypedef char *string, que simplesmente diz que queremos nomear um novo tipo,string, comochar *, ou um ponteiro para um caractere. -
Vamos imprimir uma string:
#include <cs50.h> #include <stdio.h> int main(void) { string s = "EMMA"; printf("%s\n", s); } -
Isso é familiar, mas podemos simplesmente dizer:
#include <stdio.h> int main(void) { char *s = "EMMA"; printf("%s\n", s); }- Isso também imprimirá
EMMA.
- Isso também imprimirá
-
Com
printf("%p\n", s);, podemos imprimirscomo seu valor como um ponteiro, como0x42ab52. (printfsabe ir para o endereço e imprimir a string inteira quando usamos%se passamoss, mesmo quesaponte apenas para o primeiro caractere.) - Podemos também tentar
printf("%p\n", &s[0]);, que é o endereço do primeiro caractere des, e é exatamente o mesmo que imprimirs. E imprimir&s[1],&s[2], e&s[3]nos dá os endereços que são os próximos caracteres na memória depois de&s[0], como0x42ab53,0x42ab54, e0x42ab55, exatamente um byte após o outro. - E finalmente, se tentarmos
printf("%c\n", *s);, obteremos um único caractereE, já que iremos para o endereço contido ems, que tem o primeiro caractere na string. - De fato,
s[0],s[1], es[2]na verdade são mapeados diretamente para*s,*(s+1), e*(s+2), já que cada um dos próximos caracteres está exatamente no endereço do próximo byte.
Comparar e copiar
-
Vamos olhar para
compare0:#include <cs50.h> #include <stdio.h> int main(void) { // Obter dois inteiros int i = get_int("i: "); int j = get_int("j: "); // Comparar inteiros if (i == j) { printf("Igual\n"); } else { printf("Diferente\n"); } }- Podemos compilar e executar isso, e nosso programa funciona como esperado, com os mesmos valores dos dois inteiros nos dando "Igual" e valores diferentes "Diferente".
-
Em
compare1, vemos que os mesmos valores de string estão fazendo nosso programa imprimir "Diferente":#include <cs50.h> #include <stdio.h> int main(void) { // Obter duas strings string s = get_string("s: "); string t = get_string("t: "); // Comparar endereços das strings if (s == t) { printf("Igual\n"); } else { printf("Diferente\n"); } }- Dado o que sabemos agora sobre strings, isso faz sentido porque cada variável de "string" está apontando para um local diferente na memória, onde o primeiro caractere de cada string é armazenado. Portanto, mesmo que os valores das strings sejam iguais, isso sempre imprimirá "Diferente".
- Por exemplo, nossa primeira string pode estar no endereço 0x123, a segunda pode estar no 0x456, e
sserá0x123etserá0x456, então esses valores serão diferentes. - E
get_string, o tempo todo, tem retornado apenas umchar *, ou um ponteiro para o primeiro caractere de uma string do usuário.
-
Agora vamos tentar copiar uma string:
#include <cs50.h> #include <ctype.h> #include <stdio.h> int main(void) { string s = get_string("s: "); string t = s; t[0] = toupper(t[0]); // Imprimir a string duas vezes printf("s: %s\n", s); printf("t: %s\n", t); }- Obtemos uma string
se copiamos o valor desparat. Em seguida, capitalizamos a primeira letra emt. - Mas quando executamos nosso programa, vemos que tanto
squantotagora estão capitalizados. - Como definimos
setpara os mesmos valores, eles são na verdade ponteiros para o mesmo caractere, e assim capitalizamos o mesmo caractere!
- Obtemos uma string
-
Para realmente fazer uma cópia de uma string, precisamos fazer um pouco mais de trabalho:
#include <cs50.h> #include <ctype.h> #include <stdio.h> #include <string.h> int main(void) { char *s = get_string("s: "); char *t = malloc(strlen(s) + 1); for (int i = 0, n = strlen(s); i < n + 1; i++) { t[i] = s[i]; } t[0] = toupper(t[0]); printf("s: %s\n", s); printf("t: %s\n", t); }- Criamos uma nova variável,
t, do tipochar *, comchar *t. Agora, queremos apontá-la para um novo bloco de memória grande o suficiente para armazenar a cópia da string. Commalloc, podemos alocar alguns bytes na memória (que não estão sendo usados para armazenar outros valores), e passamos o número de bytes que desejamos. Já sabemos o comprimento des, então adicionamos 1 para o caractere nulo de terminação. Portanto, nossa linha final de código échar *t = malloc(strlen(s) + 1);. - Em seguida, copiamos cada caractere, um de cada vez, e agora podemos capitalizar apenas a primeira letra de
t. E usamosi < n + 1, já que realmente queremos ir atén, para garantir que copiamos o caractere de terminação na string. - Na verdade, também podemos usar a função da biblioteca
strcpycomstrcpy(t, s)em vez do nosso loop, para copiar a stringsparat. Para ser claro, o conceito de uma “string” é da linguagem C e bem suportado; as únicas rodinhas de treinamento do CS50 são o tipostringem vez dechar *, e a funçãoget_string.
- Criamos uma nova variável,
-
Se não copiarmos o caractere nulo de terminação,
\0, e tentarmos imprimir nossa stringt,printfcontinuará e imprimirá os valores desconhecidos ou lixo que temos na memória, até que eventualmente encontre um\0, ou até mesmo possa travar completamente, já que nosso programa pode acabar tentando ler uma memória que não lhe pertence!
valgrind
- Acontece que, após concluirmos de usar uma memória que alocamos com
malloc, devemos chamarfree(como emfree(t)), que informa ao nosso computador que aqueles bytes não são mais úteis ao programa, então os bytes na memória podem ser reutilizados novamente. - Se continuássemos a executar o programa e alocar memória com
malloc, mas nunca liberar a memória após o uso, teríamos um vazamento de memória, o que tornará o computador mais lento e usará cada vez mais memória até que o computador fique sem. valgrindé uma ferramenta de linha de comando que podemos usar para executar o programa e ver se ele tem algum vazamento de memória. Podemos executar o valgrind no programa acima comhelp50 valgrind ./copye ver, a partir da mensagem de erro, que na linha 10, alocamos memória que nunca liberamos (ou “perdemos”).- Portanto, no final, podemos adicionar uma linha
free(t), que não mudará a execução do programa, mas sem erros do valgrind. -
Vamos dar uma olhada em
memory.c:// http://valgrind.org/docs/manual/quick-start.html#quick-start.prepare #include <stdlib.h> void f(void) { int *x = malloc(10 * sizeof(int)); x[10] = 0; } int main(void) { f(); return 0; }- Este é um exemplo da documentação do valgrind (valgrind é uma ferramenta real, enquanto o help50 foi escrito especificamente para nos ajudar neste curso).
- A função
faloca memória suficiente para armazenar 10 números inteiros e armazena o endereço em um ponteiro chamadox. Então, tentamos definir o 11º valor dexcomx[10]como0, que vai além do array de memória que alocamos para o programa. Isso é chamado de estouro de buffer, em que vamos além dos limites do buffer ou array e para uma memória desconhecida.
-
O valgrind também nos informará que há uma “Gravação inválida de tamanho 4” para a linha 8, onde estamos realmente tentando alterar o valor de um inteiro (de tamanho 4 bytes).
- E durante todo esse tempo, a Biblioteca CS50 tem liberado memória que foi alocada em
get_string, quando o programa termina!
Troca
- Temos duas bebidas coloridas, roxa e verde, cada uma delas em um copo. Queremos trocar as bebidas entre os dois copos, mas não podemos fazer isso sem um terceiro copo para despejar uma das bebidas primeiro.
-
Agora, digamos que queremos trocar os valores de dois números inteiros.
void swap(int a, int b) { int tmp = a; a = b; b = tmp; }- Com uma terceira variável para usar como espaço de armazenamento temporário, podemos fazer isso facilmente, colocando
aemtmp, e entãobema, e finalmente o valor original dea, agora emtmp, emb.
- Com uma terceira variável para usar como espaço de armazenamento temporário, podemos fazer isso facilmente, colocando
-
Mas, se tentarmos usar essa função em um programa, não vemos nenhuma alteração:
#include <stdio.h> void swap(int a, int b); int main(void) { int x = 1; int y = 2; printf("x é %i, y é %i\n", x, y); swap(x, y); printf("x é %i, y é %i\n", x, y); } void swap(int a, int b) { int tmp = a; a = b; b = tmp; }- Acontece que a função
swaprecebe suas próprias variáveis,aebquando elas são passadas, que são cópias dexey, e portanto, alterar esses valores não alteraxeyna funçãomain.
- Acontece que a função
Layout da memória
- Dentro da memória do nosso computador, os diferentes tipos de dados que precisam ser armazenados para o nosso programa são organizados em diferentes seções:

- A seção código da máquina é o código binário do nosso programa compilado. Quando executamos nosso programa, esse código é carregado na "parte superior" da memória.
- Globais são variáveis globais declaramos em nosso programa ou outras variáveis compartilhadas que todo o nosso programa pode acessar.
- A seção heap é uma área vazia onde o
mallocpode obter memória livre, para que nosso programa use. - A seção pilha é usada por funções em nosso programa conforme elas são chamadas. Por exemplo, nossa função
mainestá na parte inferior da pilha e tem as variáveis locaisxey. A funçãoswap, quando chamada, tem seu próprio quadro ou fatia de memória que está no topo da memória demain, com as variáveis locaisa,betmp:
- Depois que a função
swapretorna, a memória que ela estava usando é liberada para a próxima chamada de função, e nós perdemos tudo o que fizemos, além dos valores de retorno, e nosso programa volta para a função que chamouswap. - Portanto, passando os endereços de
xeydemainparaswap, podemos realmente alterar os valores dexey:
- Depois que a função
- Ao passar o endereço de
xey, nossa funçãoswappode realmente funcionar:
```
#include
void swap(int *a, int *b);
int main(void)
{
int x = 1;
int y = 2;
printf("x is %i, y is %i\n", x, y);
swap(&x, &y);
printf("x is %i, y is %i\n", x, y);
}
void swap(int *a, int *b)
{
int tmp = *a;
*a = *b;
*b = tmp;
}
```
-
Os endereços de
xeysão passados demainparaswap, e usamos a sintaxeint *apara declarar que nossa funçãoswaprecebe ponteiros. Salvamos o valor dexparatmpseguindo o ponteiroae, em seguida, pegamos o valor deyseguindo o ponteirobe o armazenamos no local para o qualaestá apontando (x). Finalmente, armazenamos o valor detmpno local apontado porb(y), e pronto. -
Se chamarmos
mallocmuitas vezes, teremos um overflow de heap, no qual acabamos passando do nosso heap. Ou, se tivermos muitas funções sendo chamadas, teremos um overflow de pilha, no qual nossa pilha também tem muitos quadros de memória alocados. E esses dois tipos de estouro são geralmente conhecidos como estouros de buffer, após os quais nosso programa (ou computador inteiro) pode travar.
get_int
-
Podemos implementar
get_intnós mesmos com uma função de biblioteca em C,scanf:#include <stdio.h> int main(void) { int x; printf("x: "); scanf("%i", &x); printf("x: %i\n", x); }scanfrecebe um formato,%i, portanto, a entrada é "escaneada" para esse formato e o endereço na memória para onde queremos que essa entrada vá. Masscanfnão tem muita verificação de erros, então podemos não obter um inteiro.
-
Podemos tentar obter uma string da mesma maneira:
#include <stdio.h> int main(void) { char *s = NULL; printf("s: "); scanf("%s", s); printf("s: %s\n", s); }- Mas, na verdade, não alocamos nenhuma memória para
s(séNULLou não aponta para nada), então, podemos querer chamarchar s[5]para alocar uma matriz de 5 caracteres para nossa string. Então,sserá tratado como um ponteiro emscanfeprintf. - Agora, se o usuário digitar uma string de comprimento 4 ou menor, nosso programa funcionará com segurança. Mas se o usuário digitar uma string maior,
scanfpoderá tentar escrever além do final da nossa matriz na memória desconhecida, fazendo com que nosso programa trave.
- Mas, na verdade, não alocamos nenhuma memória para
Arquivos
- Com a habilidade de usar ponteiros, também podemos abrir arquivos:
```c
include
include
include
int main(void) { // Abre arquivo FILE *file = fopen("phonebook.csv", "a");
// Recebe texto do usuário
char *name = get_string("Name: ");
char *number = get_string("Number: ");
// Imprime (escreve) texto no arquivo
fprintf(file, "%s,%s\n", name, number);
// Fecha arquivo
fclose(file);
} ```
fopené uma nova função que podemos usar para abrir um arquivo. Ela retornará um ponteiro para um novo tipo,FILE, que podemos ler e escrever. O primeiro argumento é o nome do arquivo, e o segundo é o modo que queremos abrir o arquivo (rpara leitura,wpara escrita, eapara anexar, ou adicionar).- Após obter algum texto, podemos usar
fprintfpara imprimir em um arquivo. -
Finalmente, fechamos o arquivo com
fclose. -
Agora podemos criar nossos próprios arquivos CSV, arquivos de valores separados por vírgulas (como uma mini-planilha), programaticamente.
JPEG
-
Também podemos escrever um programa que abre um arquivo e nos diz se é um arquivo JPEG (imagem):
#include <stdio.h> int main(int argc, char *argv[]) { // Verifica o uso if (argc != 2) { retornar 1; } // Abrir o arquivo FILE *file = fopen(argv[1], "r"); if (!arquivo) { retornar 1; } // Ler os três primeiros bytes unsigned char bytes[3]; fread(bytes, 3, 1, file); // Verificar os três primeiros bytes if (bytes[0] == 0xff && bytes[1] == 0xd8 && bytes[2] == 0xff) { printf("Talvez\n"); } mais { printf("Não\n"); } // Fechar o arquivo fclose(file); }- Agora, se executarmos este programa com
./jpeg brian.jpg, nosso programa tentará abrir o arquivo que especificamos (verificando se realmente obtemos um arquivo não nulo) e ler os três primeiros bytes do arquivo comler. - Podemos comparar os três primeiros bytes (em hexadecimal) com os três bytes necessários para iniciar um arquivo JPEG. Se eles forem iguais, então nosso arquivo provavelmente será um arquivo JPEG (embora outros tipos de arquivo ainda possam começar com esses bytes). Mas se eles não forem iguais, sabemos que definitivamente não é um arquivo JPEG.
- Agora, se executarmos este programa com
-
Podemos usar essas habilidades para ler e escrever arquivos, em particular imagens, e modificá-los alterando os bytes neles, no conjunto de problemas desta semana!