Aula 7
Planilhas
- A maioria de nós está familiarizada com planilhas, linhas de dados, com cada coluna em uma linha tendo um dado diferente relacionado entre si de alguma forma.
- Um banco de dados é um aplicativo que pode armazenar dados, e podemos pensar no Google Sheets como um desses aplicativos.
- Por exemplo, criamos um Google Form para perguntar aos alunos sobre seu programa de TV favorito e seu gênero. Vemos nas respostas que a planilha tem três colunas: "Timestamp", "title" e "genres":
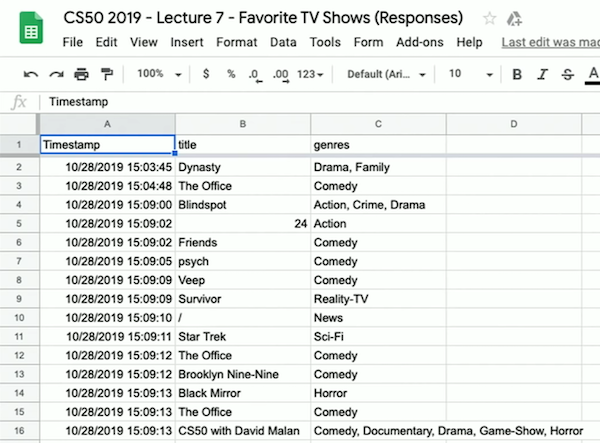
- Podemos fazer o download de um arquivo CSV da planilha com "Arquivo > Baixar", fazer o upload para nosso IDE e ver que é um arquivo de texto com valores separados por vírgula correspondendo aos dados da planilha.
-
Vamos escrever
favorites.py:import csv with open("CS50 2019 - Lecture 7 - Favorite TV Shows (Responses) - Form Responses 1.csv", "r") as file: reader = csv.DictReader(file) for row in reader: print(row["title"])- Só vamos abrir o arquivo e verificar se podemos obter o título de cada linha.
-
Agora podemos usar um dicionário para contar a quantidade de vezes em que vimos cada título, com as chaves sendo os títulos e os valores de cada chave sendo um inteiro, rastreando a quantidade de vezes que vimos aquele título:
import csv counts = {} with open("CS50 2019 - Lecture 7 - Favorite TV Shows (Responses) - Form Responses 1.csv", "r") as file: reader = csv.DictReader(file) for row in reader: title = row["title"] if title in counts: counts[title] += 1 else: counts[title] = 1 for title, count in counts.items(): print(title, count, sep=" | ")- Em cada linha podemos obter o
titlecomrow["title"]. - Aqui, se já vimos o título antes (está em
counts), podemos simplesmente adicionar 1 ao valor. Caso contrário, precisamos definir o valor inicial como 1. - Por fim, podemos imprimir as chaves e os valores do nosso dicionário com um separador para que seja um pouco mais fácil de ler.
- Em cada linha podemos obter o
-
Podemos mudar a maneira como iteramos para
for title, count in sorted(counts.items()):e veremos nosso dicionário ordenado pelas chaves, em ordem alfabética. -
Mas podemos ordenar pelos pares chave-valor no dicionário com:
def f(item): return item[1] for title, count in sorted(counts.items(), key=f, reverse=True):- Definimos uma função,
f, que apenas retorna o valor doitemno dicionário comitem[1]. A funçãosorted, por sua vez, pode usar isso como a chave para classificar os itens do dicionário. E também passaremosreverse=Truepara classificar do maior para o menor, em vez de do menor para o maior.
- Definimos uma função,
-
Na verdade, podemos definir nossa função na mesma linha, com esta sintaxe:
for title, count in sorted(counts.items(), key=lambda item: item[1], reverse=True):- Passamos um lambda, ou função anônima, como a chave, que recebe o
iteme retornaitem[1].
- Passamos um lambda, ou função anônima, como a chave, que recebe o
-
Por fim, podemos deixar todos os títulos em minúsculas com
title = row["title"].lower(), para que nossas contagens possam ser um pouco mais precisas, mesmo que os nomes não tenham sido digitados exatamente da mesma maneira.
SQL
- Veremos um novo programa em nossa janela do terminal,
sqlite3, um programa de linha de comando que nos permite usar outra linguagem, SQL (pronuncia-se como "sequel"). -
Executaremos alguns comandos para criar um novo banco de dados denominado
favorites.dbe importar nosso arquivo CSV para uma tabela denominada "favorites":~/ $ sqlite3 favorites.db SQLite version 3.22.0 2018-01-22 18:45:57 Enter ".help" for usage hints. sqlite> .mode csv sqlite> .import "CS50 2019 - Lecture 7 - Favorite TV Shows (Responses) - Form Responses 1.csv" favorites -
Vemos um
favorites.dbno nosso IDE depois de executar isto e agora podemos usar o SQL para interagir com nossos dados:sqlite> SELECT title FROM favorites; title Dynasty The Office Blindspot 24 Friends psych Veep Survivor ... -
Podemos até mesmo classificar nossos resultados:
sqlite> SELECT title FROM favorites ORDER BY title; title / 24 9009 Adventure Time Airplane Repo Always Sunny Ancient Aliens ... -
E obter uma contagem do número de vezes que cada título aparece:
sqlite> SELECT title, COUNT(title) FROM favorites GROUP BY title; title | COUNT(title) / | 1 24 | 1 9009 | 1 Adventure Time | 1 Airplane Repo | 1 Always Sunny | 1 Ancient Aliens | 1 ... -
Podemos até mesmo definir a contagem de cada título para uma nova variável,
ne encomendar os nossos resultados por isso, em ordem decrescente. Em seguida, podemos ver os 10 primeiros resultados comLIMIT 10:sqlite> SELECT title, COUNT(title) AS n FROM favorites GROUP BY title ORDER BY n DESC LIMIT 10; title | n The Office | 30 Friends | 20 Game of Thrones | 20 Breaking Bad | 14 Black Mirror | 9 Rick and Morty | 9 Brooklyn Nine-Nine | 5 Game of thrones | 5 No | 5 Prison Break | 5 -
SQL é uma linguagem que nos permite trabalhar com um banco de dados relacional, um aplicativo que nos permite armazenar dados e trabalhar com eles mais rapidamente do que com um CSV.
-
Com
.schema, podemos ver como o formato da tabela para nossos dados é criado:sqlite> .schema CREATE TABLE favoritos( "Timestamp" TEXT, "título" TEXT, "gêneros" TEXT ); -
Acontece que, ao trabalhar com dados, precisamos apenas de quatro operações:
CREATEREADUPDATEDELETE
- Em SQL, os comandos para executar cada uma dessas operações são:
INSERTSELECTUPDATEDELETE
- Primeiro, precisaremos inserir uma tabela com o comando
CREATE TABLE tabela (tipo de coluna, ...);. - O SQL também tem seus próprios tipos de dados para otimizar a quantidade de espaço usado para armazenar dados:
BLOB, para "objeto binário grande", dados binários brutos que podem representar arquivosINTEGERsmallintintegerbigint
NUMERICbooleandatedatetimenumeric(escala, precisão), que resolve a imprecisão de ponto flutuante usando quantos bits forem necessários, para cada dígito antes e depois do ponto decimaltimetimestamp
REALreal, para valores de ponto flutuanteprecisão dupla, com mais bits
TEXTchar(n), para um número exato de caracteresvarchar(n), para um número variável de caracteres, até um certo limitetext
- O SQLite é um aplicativo de banco de dados que suporta SQL, e há muitas empresas com aplicativos de servidor que suportam SQL, incluindo Oracle Database, MySQL, PostgreSQL, MariaDB e Microsoft Access.
- Depois de inserir valores, também podemos usar funções para executar cálculos:
AVGCOUNTDISTINCT, para obter valores distintos sem duplicatasMAXMIN- …
- Há também outras operações que podemos combinar conforme necessário:
WHERE, correspondendo a alguma condição estritaLIKE, correspondendo a substrings de textoLIMITGROUP BYORDER BYJOIN, combinando dados de várias tabelas
- Podemos atualizar dados com
UPDATE tabela SET coluna=valor WHERE condição;, que pode incluir 0, 1 ou mais linhas, dependendo de nossa condição. Por exemplo, podemos dizerUPDATE favoritos SET título = "The Office" WHERE título LIKE "%office", e isso definirá todas as linhas com o título contendo "office" como "The Office" para que possamos torná-las consistentes. - E podemos remover linhas correspondentes com
DELETE FROM tabela WHERE condição;, como emDELETE FROM favoritos WHERE título = "Friends";. - Podemos até excluir uma tabela inteira com outro comando,
DROP.
IMDb
- O IMDb (Internet Movie Database) tem conjuntos de dados disponíveis para download como arquivos TSV (valores separados por tabulação).
- Por exemplo, podemos baixar
title.basics.tsv.gz, que conterá dados básicos sobre os títulos:tconst, um identificador único para cada título, comott4786824titleType, o tipo de título, comotvSeriesprimaryTitle, o título principal usado, comoThe CrownstartYear, em que ano o título foi lançado, como2016genres, uma lista separada por vírgulas de gêneros, comoDrama,História
- Damos uma olhada no
title.basics.tsvdepois de descompactá-lo e vemos que as primeiras linhas são de fato os cabeçalhos que esperávamos e que cada linha tem valores separados por tabulações. Mas o arquivo tem mais de 6 milhões de linhas, então até mesmo procurar uma valor demora um pouco. - Vamos baixar o arquivo em nosso IDE com
wgete então usargunzippara descompactá-lo. Mas o nosso IDE não tem espaço suficiente, então usamos o terminal do Mac. -
Escreveremos
import.pypara ler o seguinte arquivo:import csv # Abre o arquivo TSV para leitura with open("title.basics.tsv", "r") as titles: # Como o arquivo é um arquivo TSV, podemos usar o leitor de CSV e alterar # o separador para uma tabulação. reader = csv.DictReader(titles, delimiter="\t") # Abre um novo arquivo CSV para escrita with open("shows0.csv", "w") as shows: # Cria o escritor writer = csv.writer(shows) # Escreve o cabeçalho das colunas que queremos writer.writerow(["tconst", "primaryTitle", "startYear", "genres"]) # Itera no arquivo TSV for row in reader: # Se não for um programa de TV adulto if row["titleType"] == "tvSeries" and row["isAdult"] == "0": # Escreve a linha writer.writerow([row["tconst"], row["primaryTitle"], row["startYear"], row["genres"]]) -
Agora, podemos abrir
shows0.csve ver um conjunto de dados menor. Mas, para algumas das linhas,startYeartem um valor de\N, que é um valor especial do IMDb, quando querem representar valores ausentes. Então, podermos filtrar esses valores e converter ostartYearpara um número inteiro para filtrar programas depois de 1970:... # Se o ano não for ausente (Precisamos escapar a barra invertida também) if row["startYear"] != "\\N": # Se após 1970 if int(row["startYear"]) >= 1970: # Escreve a linha writer.writerow([row["tconst"], row["primaryTitle"], row["startYear"], row["genres"]]) -
Podemos escrever um programa para pesquisar um título em particular:
import csv # Prompts o usuário pelo título title = input("Título: ") # Abre o arquivo CSV with open("shows2.csv", "r") as input: # Cria o DictReader reader = csv.DictReader(input) # Itera pelo arquivo CSV for row in reader: # Pesquisa pelo título if title.lower() == row["primaryTitle"].lower(): print(row["primaryTitle"], row["startYear"], row["genres"], sep=" | ") -
Podemos executar este programa e ver nossos resultados, mas podemos ver como o SQL pode fazer um trabalho melhor.
-
No Python, podemos nos conectar a um banco de dados SQL e ler nosso arquivo nele uma vez, para que possamos fazer muitas consultas sem escrever novos programas e sem ter que ler o arquivo inteiro todas as vezes.
-
Vamos fazer isso mais facilmente com a biblioteca CS50:
import cs50 import csv # Cria um banco de dados abrindo e fechando um arquivo vazio primeiro open(f"shows3.db", "w").close() db = cs50.SQL("sqlite:///shows3.db") # Cria uma tabela chamada `shows` e especifica as colunas que queremos, # todas as quais serão textos, exceto `startYear` db.execute("CREATE TABLE shows (tconst TEXT, primaryTitle TEXT, startYear NUMERIC, genres TEXT)") # Abre o arquivo TSV # https://datasets.imdbws.com/title.basics.tsv.gz with open("title.basics.tsv", "r") as titles: # Cria o DictReader reader = csv.DictReader(titles, delimiter="\t") # Itera pelo arquivo TSV for row in reader: # Se não for um programa de TV adulto if row["titleType"] == "tvSeries" and row["isAdult"] == "0": # Se o ano não estiver faltando if row["startYear"] != "\\N": # Se desde 1970 startYear = int(row["startYear"]) if startYear >= 1970: # Insere o programa substituindo os valores em cada espaço reservado ? db.execute("INSERT INTO shows (tconst, primaryTitle, startYear, genres) VALUES(?, ?, ?, ?)", row["tconst"], row["primaryTitle"], startYear, genres) -
Agora podemos executar
sqlite3 shows3.dbe executar comandos como antes, comoSELECT * FROM shows LIMIT 10;. - Com
SELECT COUNT(*) FROM shows;podemos ver que há mais de 150.000 programas em nossa tabela e comSELECT COUNT(*) FROM shows WHERE startYear = 2019;, vemos que houve mais de 6.000 este ano.
Várias tabelas
-
Mas cada uma das linhas terá apenas uma coluna para gêneros e os valores são vários gêneros juntos. Portanto, podemos retornar ao nosso programa de importação e adicionar outra tabela:
import cs50 import csv # Criar banco de dados open(f"shows4.db", "w").close() db = cs50.SQL("sqlite:///shows4.db") # Criar tabelas db.execute("CREATE TABLE shows (id INT, title TEXT, year NUMERIC, PRIMARY KEY(id))") # A tabela `genres` terá uma coluna chamada `show_id` que referencia # a tabela `shows` acima db.execute("CREATE TABLE genres (show_id INT, genre TEXT, FOREIGN KEY(show_id) REFERENCES shows(id))") # Abrir arquivo TSV # https://datasets.imdbws.com/title.basics.tsv.gz with open("title.basics.tsv", "r") as titles: # Criar DictReader reader = csv.DictReader(titles, delimiter="\t") # Iterar sobre o arquivo TSV for row in reader: # Se não for um programa de TV adulto if row["titleType"] == "tvSeries" and row["isAdult"] == "0": # Se o ano não estiver faltando if row["startYear"] != "\\N": # Se for depois de 1970 startYear = int(row["startYear"]) if startYear >= 1970: # Aparar prefixo da tconst id = int(row["tconst"][2:]) # Inserir programa db.execute("INSERT INTO shows (id, title, year) VALUES(?, ?, ?)", id, row["primaryTitle"], startYear) # Inserir gêneros if row["genres"] != "\\N": for genre in row["genres"].split(","): db.execute("INSERT INTO genres (show_id, genre) VALUES(?, ?)", id, genre)- Portanto, agora, nossa tabela
showsnão tem mais uma colunagenres, mas, em vez disso, temos uma tabelagenrescom cada linha representando um programa e um gênero associado. Agora, um programa específico pode ter vários gêneros que podemos procurar, e podemos obter outros dados sobre o programa da tabelashowsfornecido seu ID.
- Portanto, agora, nossa tabela
-
De fato, podemos combinar as duas tabelas com
SELECT * FROM shows WHERE id IN (SELECT show_id FROM genres WHERE genre = "Comedy") AND year = 2019;. Estamos filtrando nossa tabelashowspelos IDs nos quais o ID da tabelagenrestem um valor "Comedy" para a colunagenre, e tem o valor 2019 para a colunayear. - Nossas tabelas são mais ou menos assim:

- Uma vez que o ID na tabela
genrevem da tabelashows, nós o chamamos deshow_id. E a seta indica que um único show ID pode ter muitas linhas correspondentes na tabelagenres.
- Uma vez que o ID na tabela
- Vemos que alguns conjuntos de dados da IMDb, como
title.principals.tsv, têm apenas IDs para determinadas colunas que precisaremos procurar em outras tabelas. - Ao ler as descrições para cada tabela, podemos ver que todos os dados podem ser usados para construir estas tabelas:
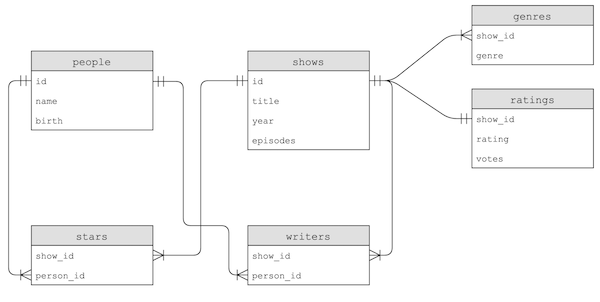
- Repare que, por exemplo, o nome de uma pessoa também poderia ser copiado para as tabelas
starsouwriters, mas apenas operson_idé usado para vincular aos dados na tabelapeople. Desta forma, precisamos atualizar o nome em apenas um lugar se precisarmos fazer uma alteração.
- Repare que, por exemplo, o nome de uma pessoa também poderia ser copiado para as tabelas
- Abriremos um banco de dados,
shows.db, com essas tabelas para ver mais alguns exemplos. - Faremos o download de um programa chamado DB Browser for SQLite, que terá uma interface gráfica de usuário para navegar em nossas tabelas e dados. Podemos usar a guia "Execute SQL" para executar o SQL diretamente no programa também.
- Podemos executar
SELECT * FROM shows JOIN genres ON show.id = genres.show_id;para unir duas tabelas por IDs correspondentes em colunas que especificamos. Então, obteremos uma tabela mais ampla, com colunas de cada uma dessas duas tabelas. - Podemos pegar o ID de uma pessoa e encontrá-la em shows com
SELECT * FROM stars WHERE person_id = 1122;, mas podemos fazer uma consulta dentro de nossa consulta comSELECT show_id FROM stars WHERE person_id = (SELECT id FROM people WHERE name = "Ellen DeGeneres");. - Isso nos devolve o
show_id, então para obter os dados do programa podemos executar:SELECT * FROM shows WHERE id IN (...);com...sendo a consulta acima. -
Podemos obter os mesmos resultados com:
SELECT title FROM people JOIN stars ON people.id = stars.person_id JOIN shows ON stars.show_id = shows.id WHERE name = "Ellen DeGeneres"- Unimos a tabela
peoplecom a tabelastars, e então com a tabelashowsespecificando colunas que devem corresponder entre as tabelas e, em seguida, selecionando apenas otitlecom um filtro no nome. - Mas agora também podemos selecionar outros campos em nossas tabelas combinadas.
- Unimos a tabela
-
Acontece que podemos especificar colunas de nossas tabelas para serem tipos especiais, tais como:
PRIMARY KEY, usado como o identificador primário para uma linhaFOREIGN KEY, que aponta para uma linha em outra tabelaUNIQUE, o que significa que ele precisa ser único nesta tabelaINDEX, que pede ao nosso banco de dados para criar um índice para consultar mais rapidamente com base nesta coluna. Um índice é uma estrutura de dados como uma árvore, que nos ajuda a procurar valores.
- Podemos criar um índice com
CREATE INDEX person_index ON stars (person_id);. Então a colunaperson_idterá um índice chamadoperson_index. Com os índices corretos, nossa consulta de junção é centenas de vezes mais rápida.
Problemas
- Um problema com bancos de dados são as condições de corrida, onde o tempo de duas ações ou eventos causa comportamento inesperado.
- Por exemplo, considere dois colegas de quarto e uma geladeira compartilhada em seu dormitório. O primeiro colega de quarto chega em casa e vê que não há leite na geladeira. Então, o primeiro colega de quarto vai à loja para comprar leite e, enquanto está na loja, o segundo colega de quarto chega em casa, vê que não há leite e vai a outra loja para pegar leite. Mais tarde, haverá dois jarros de leite na geladeira. Ao deixar um bilhete, podemos resolver esse problema. Podemos até trancar a geladeira para que nosso colega de quarto não possa verificar se há leite, até que voltemos.
-
Isso pode acontecer em nosso banco de dados se tivermos algo assim:
rows = db.execute("SELECT likes FROM posts WHERE id=?", id); likes = rows[0]["likes"] db.execute("UPDATE posts SET likes = ?", likes + 1);- Primeiro, estamos obtendo o número de curtidas em uma postagem com um determinado ID. Então, definimos o número de curtidas para aquele número mais um.
- Mas agora, se tivermos dois servidores web diferentes tentando adicionar uma curtida, ambos podem defini-la para o mesmo valor em vez de realmente adicionar um a cada vez. Por exemplo, se houver 2 curtidas, ambos os servidores verificarão o número de curtidas, verão que há 2 e definirão o valor como 3. Uma das curtidas será então perdida.
-
Para resolver isso, podemos usar transações, onde um conjunto de ações é garantido que aconteça junto.
- Outro problema no SQL é chamado de ataque de injeção de SQL, onde um adversário pode executar seus próprios comandos em nosso banco de dados.
- Por exemplo, alguém pode tentar digitar
malan@harvard.edu'--como seu e-mail. Se tivermos uma consulta SQL que é uma string formatada (sem escape ou substituição de caracteres perigosos da entrada), comof"SELECT * FROM users WHERE username = '{username}' AND password = '{password}'", a consulta terminará sendof"SELECT * FROM users WHERE username = 'malan@harvard.edu'--' AND password = '{password}'", que na verdade selecionará a linha ondeusername = 'malan@harvard.edu'e transformará o resto da linha em um comentário. Para evitar isso, devemos usar os espaços reservados?para que nossa biblioteca SQL escape automaticamente as entradas do usuário.