Lecture 5
Ponteiros
-
Na última vez, aprendemos sobre ponteiros,
malloce outras ferramentas úteis para trabalhar com memória. -
Vamos revisar este trecho de código:
int main(void) { int *x; int *y; x = malloc(sizeof(int)); *x = 42; *y = 13; }-
Aqui, as duas primeiras linhas de código em nossa função
mainestão declarando dois ponteiros,xey. Em seguida, alocamos memória suficiente para umintcommalloce armazenamos o endereço retornado pelomallocemx. -
Com
*x = 42;, vamos para o endereço apontado porxe armazenamos o valor42nesse local. -
A última linha, no entanto, contém um bug porque não sabemos qual é o valor de
y, uma vez que nunca atribuímos um valor a ele. Em vez disso, podemos escrever:y = x; *y = 13;- E isso fará com que
yaponte para o mesmo local quexe, em seguida, defina aquele valor para13.
- E isso fará com que
-
-
Damos uma olhada em um pequeno clipe, Pointer Fun with Binky, que também explica esse trecho de código de forma animada!
Redimensionando matrizes
-
Na segunda semana, aprendemos sobre matrizes, onde podemos armazenar o mesmo tipo de valor em uma lista, lado a lado. Mas precisamos declarar o tamanho das matrizes quando as criamos e, quando queremos aumentar o tamanho da matriz, a memória ao seu redor pode ser ocupada por outros dados.
-
Uma solução pode ser alocar mais memória em uma área maior que esteja livre e mover nossa matriz para lá, onde ela terá mais espaço. Mas precisaremos copiar nossa matriz, o que se torna uma operação com tempo de execução de O(n), pois precisamos copiar cada um dos n elementos em uma matriz.
-
Podemos escrever um programa como o seguinte para fazer isso em código:
#include <stdio.h> #include <stdlib.h> int main(void) { // Aqui, alocamos memória suficiente para armazenar três inteiros, e nossa variável // lista apontará para o primeiro inteiro. int *lista = malloc(3 * sizeof(int)); // Devemos verificar se alocamos memória corretamente, já que o malloc pode // falhar em nos fornecer memória livre suficiente. if (lista == NULL) { return 1; } // Com essa sintaxe, o compilador fará a aritmética de ponteiros para nós e // calculará o byte na memória que lista[0], lista[1] e lista[2] mapeiam, // já que os inteiros têm tamanho de 4 bytes. lista[0] = 1; lista[1] = 2; lista[2] = 3; // Agora, se quisermos redimensionar nossa matriz para conter 4 inteiros, tentaremos alocar // memória suficiente para eles e temporariamente usaremos tmp para apontar para o primeiro: int *tmp = malloc(4 * sizeof(int)); if (tmp == NULL) { return 1; } // Agora, copiamos os inteiros da matriz antiga para a nova matriz ... for (int i = 0; i < 3; i++) { tmp[i] = lista[i]; } // ... e adicionamos o quarto inteiro: tmp[3] = 4; // Devemos liberar a memória original alocada para lista, é por isso que precisamos de uma // variável temporária para apontar para a nova matriz ... free(lista); // ... e agora podemos definir nossa variável lista para apontar para a nova matriz que o // tmp aponta: lista = tmp; // Agora, podemos imprimir a nova matriz: for (int i = 0; i < 4; i++) { printf("%i\n", lista[i]); } // Finalmente, liberamos a memória da nova matriz. free(lista); } -
Acontece que existe uma função útil chamada
realloc, que permite realocar alguma memória:#include <stdio.h> #include <stdlib.h> int main(void) { int *lista = malloc(3 * sizeof(int)); if (lista == NULL) { return 1; } lista[0] = 1; lista[1] = 2; lista[2] = 3; // Aqui, passamos para realloc nossa matriz original, para qual lista aponta, e ela irá // retornar um novo endereço para uma nova matriz, com os dados antigos copiados: int *tmp = realloc(lista, 4 * sizeof(int)); if (tmp == NULL) { return 1; } // Agora, tudo o que precisamos fazer é lembrar a localização da nova matriz: lista = tmp; lista[3] = 4; for (int i = 0; i < 4; i++) { printf("%i\n", lista[i]); } free(lista); }'
Estruturas de dados
- Estruturas de dados são construções de programação que nos permitem armazenar informações em diferentes layouts na memória do nosso computador.
-
Para construir uma estrutura de dados, precisamos de algumas ferramentas que vimos anteriormente:
structpara criar tipos de dados personalizados.para acessar propriedades em uma estrutura*para ir para um endereço na memória apontado por um ponteiro
Listas Encadeadas
-
Com uma lista encadeada, podemos armazenar uma lista de valores que pode ser facilmente expandida, armazenando valores em diferentes partes da memória:

- Isso é diferente de uma matriz, pois nossos valores não estão mais próximos um do outro na memória.
-
Podemos ligar nossa lista alocando, para cada elemento, memória suficiente para o valor que queremos armazenar e o endereço do próximo elemento:
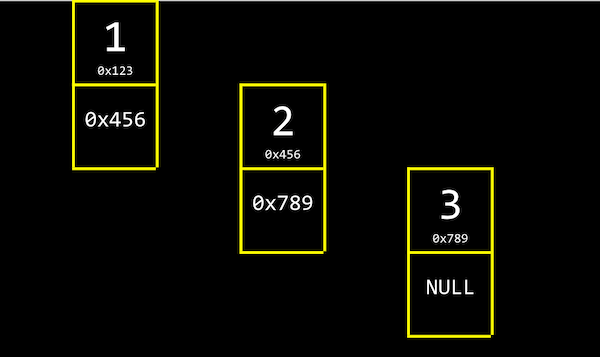
- A propósito,
NULrefere-se a\0, um caractere que termina uma string, eNULLrefere-se a um endereço de todos os zeros, ou um ponteiro nulo que podemos pensar como apontando para nenhum lugar.
- A propósito,
-
Ao contrário do que podemos fazer com matrizes, não podemos mais acessar elementos em uma lista encadeada aleatoriamente. Por exemplo, não podemos mais acessar o quinto elemento da lista calculando onde ele está, em tempo constante. (Uma vez que sabemos que as matrizes armazenam elementos lado a lado, podemos adicionar 1, ou 4, ou o tamanho do nosso elemento, para calcular endereços.) Em vez disso, precisamos seguir o ponteiro de cada elemento, um de cada vez. E precisamos alocar o dobro de memória do que precisávamos antes para cada elemento.
-
No código, podemos criar nossa própria struct chamada
node(como um nó de um gráfico em matemática), e precisamos armazenar tanto umintcomo um ponteiro para o próximonodechamadonext:typedef struct node { int number; struct node *next; } node;- Começamos essa struct com
typedef struct nodepara que possamos nos referir a umnodedentro de nossa struct.
- Começamos essa struct com
-
Podemos construir uma lista encadeada no código a partir de nossa struct. Primeiro, vamos querer lembrar de uma lista vazia, para que possamos usar o ponteiro nulo:
node *list = NULL;. -
Para adicionar um elemento, primeiro precisaremos alocar algum espaço na memória para um nó e definir seus valores:
node *n = malloc(sizeof(node)); // Queremos ter certeza de que malloc teve sucesso em obter memória para nós: if (n != NULL) { // Isto é equivalente a (*n).number, onde primeiro vamos para o nó apontado // por n e, em seguida, definimos a propriedade number. Em C, também podemos // usar esta notação de seta: n->number = 2; // Em seguida, precisamos armazenar um ponteiro para o próximo nó em nossa lista, mas o // novo nó não vai apontar para nada (por enquanto): n->next = NULL; } -
Agora nossa lista pode apontar para esse nó:
list = n;:
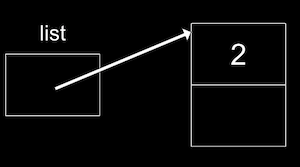
-
Para adicionar à lista, criaremos um novo nó da mesma maneira, talvez com o valor 4. Mas agora precisamos atualizar o ponteiro em nosso primeiro nó para apontar para ele.
-
Como nosso ponteiro
listaponta apenas para o primeiro nó (e não podemos ter certeza de que a lista tem apenas um nó), precisamos “seguir as migalhas” e seguir o ponteironextde cada nó:// Crie um ponteiro temporário para o que list está apontando node *tmp = list; // Enquanto o nó tiver um próximo ponteiro ... while (tmp->next != NULL) { // ... defina o temporário para o próximo nó tmp = tmp->next; } // Agora, tmp aponta para o último nó em nossa lista e podemos atualizar seu próximo // ponteiro para apontar para nosso novo nó. -
Se quisermos inserir um nó no início de nossa lista encadeada, precisaremos atualizar cuidadosamente nosso nó para apontar para o seguinte, antes de atualizar a lista. Caso contrário, perderemos o resto de nossa lista:
// Aqui, estamos inserindo um nó no início da lista, então queremos que seu // próximo ponteiro aponte para a lista original, antes de apontar a lista para // o n. n->next = list; list = n; -
E para inserir um nó no meio de nossa lista, podemos percorrer a lista, seguindo cada elemento um de cada vez, comparando seus valores e mudando os ponteiros
nextcom cuidado também. -
Com alguns voluntários no palco, simulamos uma lista, com cada voluntário atuando como a variável
listou um nó. À medida que inserimos nós na lista, precisamos de um ponteiro temporário para seguir a lista e garantir que não percamos nenhuma parte dela. Nossa lista encadeada aponta apenas para o primeiro nó em nossa lista, portanto, só podemos olhar um nó de cada vez, mas podemos alocar dinamicamente mais memória à medida que precisamos expandir nossa lista. -
Agora, mesmo que a nossa lista encadeada esteja ordenada, o tempo de execução de pesquisá-la será O(n), já que precisamos seguir cada nó para verificar seus valores e não sabemos onde estará o meio da nossa lista.
-
Podemos combinar todos os trechos de código em um programa completo:
#include <stdio.h> #include <stdlib.h> // Representa um nó typedef struct node { int number; struct node *next; } node; int main(void) { // Lista de tamanho 0, inicialmente não apontando para nada node *list = NULL; // Adicionar número à lista node *n = malloc(sizeof(node)); if (n == NULL) { return 1; } n->number = 1; n->next = NULL; // Criamos nosso primeiro nó, armazenamos o valor 1 nele e deixamos o próximo // ponteiro apontar para nada. Em seguida, nossa variável de lista pode apontar para ele. list = n; // Adicionar número à lista n = malloc(sizeof(node)); if (n == NULL) { return 1; } n->number = 2; n->next = NULL; // Agora, nós vamos ao nosso primeiro nó para o qual a lista aponta e definimos o próximo ponteiro // sobre ele para apontar para o nosso novo nó, adicionando-o ao final da lista: list->next = n; // Adicionar número à lista n = malloc(sizeof(node)); if (n == NULL) { return 1; } n->number = 3; n->next = NULL; // Podemos seguir vários nós com esta sintaxe, usando o ponteiro próximo // repetidamente, para adicionar nosso terceiro novo nó ao final da lista: list->next->next = n; // Normalmente, porém, gostaríamos de ter um loop e uma variável temporária para adicionar // um novo nó à nossa lista. // Imprimir lista // Aqui podemos percorrer todos os nós em nossa lista com uma variável temporária // Primeiro, temos um ponteiro temporário, tmp, que aponta para a // lista. Em seguida, nossa condição para continuar é que tmp não seja NULO e // finalmente, atualizamos
Mais estruturas de dados
-
Uma árvore é outra estrutura de dados em que cada nó aponta para outros dois nós, um para a esquerda (com um valor menor) e outro para a direita (com um valor maior):
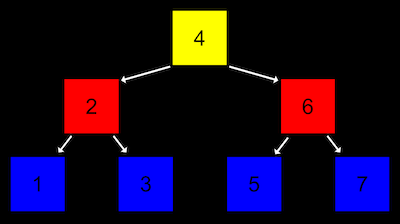
- Note que agora há duas dimensões nessa estrutura de dados, onde alguns nós estão em diferentes "níveis" em relação aos outros. E podemos imaginar que isso seja implementado com uma versão mais complexa de um nó em uma lista encadeada, onde cada nó não tem apenas um, mas dois ponteiros, um para o valor "no meio da metade esquerda" e outro para o valor "no meio da metade direita". E todos os elementos à esquerda de um nó são menores e todos os elementos à direita são maiores.
- Isso é chamado de árvore binária de busca porque cada nó tem no máximo dois filhos, ou nós para os quais está apontando, e árvore de busca porque está ordenada de uma maneira que nos permite fazer buscas corretamente.
- E, como em uma lista encadeada, vamos querer manter um ponteiro apenas para o início da lista, mas neste caso queremos apontar para a raiz, ou seja, o nó central superior da árvore (o 4).
-
Agora, podemos facilmente fazer uma busca binária e, como cada nó está apontando para outro, também podemos inserir nós na árvore sem movê-los todos como teríamos que fazer em um array. A busca recursiva nesta árvore seria algo como:
typedef struct node { int number; struct node *left; struct node *right; } node; // Aqui, *tree é um ponteiro para a raiz de nossa árvore. bool search(node *tree) { // Precisamos de um caso base, se a árvore atual (ou parte da árvore) for NULA, // para retornar false: if (tree == NULL) { return false; } // Agora, dependendo se o número no nó atual é maior ou menor, // podemos apenas olhar para o lado esquerdo ou direito da árvore: else if (50 < tree->number) { return search(tree->left); } else if (50 > tree->number) { return search(tree->right); } // Caso contrário, o número deve ser igual ao que procuramos: else { return true; } } -
O tempo de execução para pesquisar em uma árvore é O(log n), e inserir nós mantendo a árvore equilibrada também é O(log n). Ao gastarmos um pouco mais de memória e tempo para manter a árvore, agora temos uma pesquisa mais rápida em comparação com uma simples lista encadeada.
-
Uma estrutura de dados com tempo de pesquisa quase constante é uma tabela de dispersão (hash table), que é uma combinação de um array e uma lista encadeada. Temos um array de listas encadeadas, e cada lista encadeada no array tem elementos de uma determinada categoria. Por exemplo, no mundo real, podemos ter muitos crachás de identificação e podemos classificá-los em 26 compartimentos, um rotulado com cada letra do alfabeto, para que possamos encontrar os crachás de identificação olhando em apenas um compartimento.
-
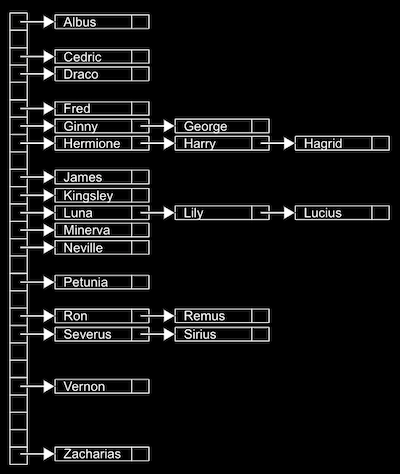
Podemos implementar isso em uma tabela de dispersão com um array de 26 ponteiros, cada um apontando para uma lista encadeada para uma letra do alfabeto:
-
Como temos acesso aleatório com arrays, podemos adicionar elementos rapidamente, e também indexar rapidamente um compartimento.
-
Um compartimento pode ter vários valores correspondentes, então usaremos uma lista encadeada para armazenar todos eles horizontalmente. (Chamamos isso de colisão, quando dois valores correspondem de alguma maneira.)
-
Isso é chamado de tabela de dispersão porque usamos uma função de dispersão, que recebe uma entrada e a mapeia para um compartimento em que deve ser colocada. Em nosso exemplo, a função de dispersão está apenas olhando para a primeira letra do nome, então pode retornar
0para "Albus" e25para "Zacharias". -
Mas no pior caso, todos os nomes podem começar com a mesma letra, então podemos acabar com o equivalente a uma única lista encadeada novamente. Podemos olhar para as primeiras duas letras e alocar compartimentos suficientes para 26*26 possíveis valores dispersados, ou até mesmo as primeiras três letras, e agora precisaríamos de 26*26*26 compartimentos. No entanto, ainda poderíamos ter um pior caso em que todos os nossos valores comecem com os mesmos três caracteres, portanto o tempo de execução para pesquisa é O(n). Na prática, porém, podemos chegar mais perto de O(1) se tivermos cerca de tantos compartimentos quanto valores possíveis, especialmente se tivermos uma função de dispersão ideal, onde podemos classificar nossas entradas em compartimentos únicos.
-
Podemos usar outra estrutura de dados chamada árvore trie (lê-se como "try" e é a abreviação de "retrieval"):
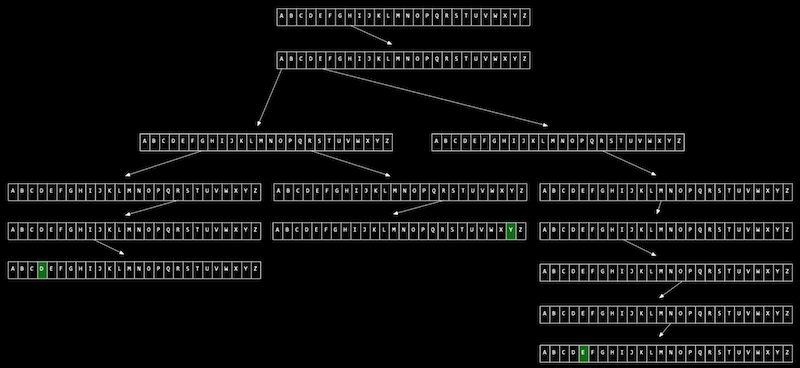
- Imagine que queremos armazenar um dicionário de palavras de maneira eficiente e ser capazes de acessar cada uma delas em tempo constante. Um árvore trie é como uma árvore, mas cada nó é um array. Cada array terá cada letra, de A a Z, armazenada. Para cada palavra, a primeira letra apontará para um array, onde a próxima letra válida apontará para outro array, e assim por diante, até chegarmos a algo que indique o final de uma palavra válida. Se a palavra não estiver no trie, então um dos arrays não terá um ponteiro ou caractere de finalização para a nossa palavra. Agora, mesmo se a nossa estrutura de dados tiver muitas palavras, o tempo de busca será apenas o comprimento da palavra que estamos procurando, e isso pode ser um máximo fixo, então temos O(1) para busca e inserção. O custo disso, porém, é 26 vezes mais memória do que precisamos para cada caractere.
-
Existem até construções de nível mais alto, estruturas de dados abstratas, onde usamos nossos blocos de construção de arrays, listas encadeadas, tabelas de dispersão e árvores trie para implementar uma solução para algum problema.
-
Por exemplo, uma estrutura de dados abstrata é uma fila, onde queremos ser capazes de adicionar valores e remover valores de forma que o primeiro a entrar seja o primeiro a sair (FIFO). Para adicionar um valor, podemos enfileirá-lo, e para remover um valor, podemos desenfileirá-lo. E podemos implementar isso com um array que redimensionamos à medida que adicionamos itens, ou uma lista encadeada onde apendicamos valores ao final.
-
Uma estrutura de dados "oposta" seria uma pilha, onde os itens adicionados mais recentemente (empilhados) são removidos (desempilhados) primeiro, em uma forma de último a entrar, primeiro a sair (LIFO). Nossa caixa de entrada de e-mail é uma pilha, onde nossos e-mails mais recentes estão no topo.
-
Outro exemplo é um dicionário, onde podemos mapear chaves para valores, ou strings para valores, e podemos implementar um com uma tabela de dispersão onde uma palavra vem com alguma outra informação (como sua definição ou significado).
-
Vamos dar uma olhada em “Jack Learns the Facts About Queues and Stacks”, uma animação sobre essas estruturas de dados.